
This application is part of a service-based, cloud-native system for production planning and scheduling (Advanced Planning and Scheduling) and production tracking (Manufacturing Execution System). As of the time of writing this post, development has been completed and the system is being piloted at two major pharmaceutical plants, while several others have expressed strong interest in its adoption. This post describes the planning/scheduling application of the system.
The APS subsystem allows for entering resources and creating manufacturing recipes, which are then combined to create manufacturing schedules. Users are allowed to modify the produced schedules and evaluate the end result via various visualization tools (mainly based on Gantt and line charts).
The application can have multiple tenants, each of them owning one or more workspaces. Workspaces contain resources, recipes, as well as a number of scheduling boards, which contain schedules that involve workspace resources and recipes. Multiple scheduling boards within the same workspace, allow for experimenting with various scenarios (what-if or others) on the same resources, in isolation of one another. An ancillary application allows for demo users to be registered online and have their registrations approved by internal users.
The application architecture is based on eShopOnContainers (https://learn.microsoft.com/en-us/dotnet/architecture/cloud-native/introduce-eshoponcontainers-reference-app) and consists of 3 applications for Planning (APS), Production (MES), Admin, each, with its own BFF, API, and SPA:
- Planning is a Domain-Driven Design microservice using DDD patterns and EF Core with a relational database. This is where the vast majority of the functionality resides (namely modelling and scheduling).
- Production is a CRUD microservice, which uses a document database. It allows for accessing schedule information on the plant floor, as well as issuing updates on actual schedule execution (i.e. schedule deviations).
- Admin is a CRUD microservice using EF Core with a relational database, helping with user registration and various other admin tasks.
Schedules created in the Planning application are published to the production database. Expensive joins only happen once during publishing, while subsequent access of the published data is served by the document database, which embeds entities and relationships for performance.
BFFs invoke internally the APIs via GRPC. Since the entire system uses .NET, we went for code-first GRPC using protobuf-net.Grpc. Each API service includes a project with the contracts and the DTOs necessary for clients to access the API.
Services exchange messages by way of an event bus that is built on top of Rabbit MQ. For example, the creation of a new user in the Admin app, raises an event so that the Planning app also creates that user in its local database.
All three SPAs are written in React with hooks and utilize a large array of standardized components built in-house, specifically for the application needs.
Functionality at a glance:
- Landing page for creating sample or empty workspaces and scheduling boards in just a couple of clicks.
- Nested tables for managing workspaces and scheduling boards. New workspaces/scheduling boards can be added by just typing the desired name in the placeholder row. Information can be changed in place.

- Ordered tables that support easily adding new rows and drag-and-drop reordering functionality.

- Side panel for viewing/editing entity details: Consists of tabs at the top and groups within each tab. Each group originally appears in read-only format with a synopsis of the selected options and expands to an edit form by clicking the edit button. Multiple, nested side panels can be opened one over the other. Users can freely open side panels for other entities without closing the currently open side panel, unless unsaved information has been entered. Simple options, such as a lone check box, are posted directly to the back end without the need for editing a form.

- Form validation with hard and soft validation errors: Hard validation errors refer to data type mismatches and general errors; soft validation errors only appear when the erroneous value is active (include errors involving the combination of multiple values).

- Advanced scheduling algorithm that takes into account task precedence as well as resource requirement information and produces tight, feasible schedules.
- Equipment Occupancy Gantt chart: Displays the scheduling outcome from a resource standpoint and allows for examining various aspects of it. Supports dependency display, scaling, fit-to-window modes etc.

- Process Gantt chart: Displays the scheduling outcome from a process standpoint on various process levels.

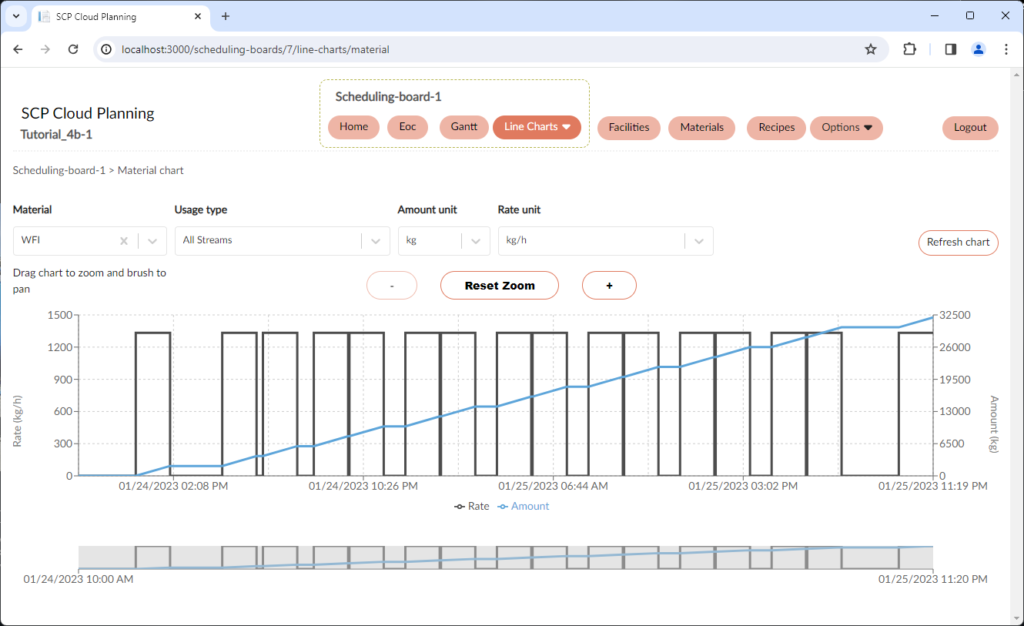
- Resource profile chart: Displays the consumptions/production of resources/products over time. Allows for zooming, scrolling, and hovering for retrieving point information.
- Inventory chart: Displays inventory levels for vessel equipment. Like the resource profile chart, it allows for zooming, scrolling, and hovering for retrieving point information.

- Multi-column sorting functionality for tables: Allows for sorting on multiple columns in the desired order, ascending or descending (e.g. rows with the same value in first column will be sorted based on the second column etc.).

- Powerful filtering functionality for tables: Allows for multiple filters combined using an “or” or an “and” relationship. For each column datatype, various different filtering options are available.

Key technologies:
- Multi-service architecture back end with ASP.NET Core.
- EF Core
- xUnit
- Mediatr
- Automapper
- GRPC
- React front ends.
- Scss
- Rabbit MQ/Event bus
- Keycloack SSO
- Docker
- SQL Server
- MongoDb
Technical highlights:
- Multi-service functional testing: Devised a technique for in-process functional testing of the BFF/API combination with a real database. The BFF WebApplicationFactory is injected with the API WebApplicationFactory, and uses the APIs default client as the HTTP Client to the registered GRPC services. Overall, over 25K lines of testing code.
- Domain-driven design with a clean architecture project layout for the Planning service. Domain project has no dependencies on database or application code. At every request, the Planning.Api project retrieves the necessary database entities with the help of EF Core and evokes the appropriate domain method for the required functionality.
- Support for advanced enumeration classes and value objects database mapping by way of EF Core custom converters and json serialization. Enumerations objects are statically created in code (only a single instance of each enumeration member is present in memory) and serialized to json when stored in the database. Upon retrieval from the database, the converter looks up the appropriate enumeration and assigns the relevant instance where a reference is needed.
- Elaborate modelling of physical quantities, physical units, and physical amounts. Each physical quantity (member of the relevant enumeration) is associated with the data type representing the physical units for that physical quantity (also an enumeration), while each physical unit references the physical quantity it belongs to. A physical amount value object contains the amount value and a reference to a physical unit. Conversion factors stored with the physical unit, allow for dynamic conversion between different units of the same physical quantity.
- Filtering/sorting extensions using LINQ expressions and Automapper Expression Translation. These extensions support specifying filtering and sorting criteria to LINQ IQueryable expressions based on the DTO fields. The expressions are then translated to domain entity fields, allowing for generic filtering/sorting just by specifying the names of the DTO properties.
- Include extensions. Created extensions that allow for reusable Include chains, each for a different subtree of the object hierarchy. These extensions can be mixed and matched to achieve the desired join outcome. Include chains for entities that need to always be retrieved along with their navigation properties can be centrally declared and maintained.
- Code-first examples for creating sample workspaces and scheduling algorithm consistency testing. Key example workspaces are created in code so that the entire workspace contents can be referenced by following the workspace navigation properties (the workspace is the top-level entity). The scheduling algorithm is then employed to produce a schedule for a sample scheduling board in the workspace. When used for testing, the created schedule can be asserted against some well-known KPIs in order to detect any deviations from the expected outcome (useful when making changes to the scheduling algorithm and want to ensure consistency with baseline scenarios). When used for sample workspace creation, the new workspace is given a new name, assigned to the user that ordered for its creation and inserted to the database for future use.
- Multi-tenancy and workspace isolation using EF Core DbContext query filters. The application is capable of hosting multiple organizations, each owning one or more workspaces, all in the same database. The workspace is the top-level, self-containing entity for the application: references between workspaces are not allowed. Workspace isolation is achieved through a workspace id query filter that is applied to all database entities by joining the entity all the way up to the containing workspace. Self-referencing consistency within a workspace is achieved by requiring that references are set up by entity rather than database id (reference ids received from the front end are used to look up the relevant entities to be used in navigation properties; if the entities belong to a different workspace they will not be returned by the query). Workspaces and their entities are further protected from unauthorized use by filtering on the organization and user id.
- Scheduling locks and request queueing for concurrency control and congestion avoidance. Scheduling operations are expensive and could overwrite the outcomes of like operations that run concurrently, so only a single such operation can be run within a certain scheduling board at any given moment. Scheduling requests that arrive while another scheduling operation is ongoing are queued, ultimately receiving the result of the already active operation, when it finally completes. With the help of SemaforeSlim, we created a locking service that will either grant resource access immediately (if the resource is available), or cause the requestor to await until the resource is freed.
- Copying extensions that can be used to clone an arbitrary entity or load it with data from another entity of the same type. The extensions are based on reflection and dynamically take into account the type of each entity property (enumeration, entity, many-to-many class, value object etc.) and accordingly copy the reference or deep copy the object.
- Integrated error reporting from the domain all the way to the front end. Each exception thrown in the domain receives contains one a predefined error codes along with a message that describes the error. The error code and message travel via the internal GRPC connection all the way to the front end, while all erroneous responses appear as http error code 422. The front end can either directly display the error message, or, for multilingual applications, map the error code to the appropriate message for the selected language.
- Standalone front-end application for offline visualization of test cases. Offline development of the scheduling algorithm (using the domain project as an SUT, without having to run the entire application), was soon identified as a very element of the development process for reasons of productivity, on-boarding time, outcome consistency etc. Such offline development required a way for visualizing the scheduling outcome. Thus, we created a simple React application which fed our in-house Gantt component with json data read from the file system. While is the application is run locally with npm start, domain scheduling tests export the scheduling outcomes to the predetermined file system locations and the front-end application automatically refreshes the charts with the exported data.